Introduction to machine learning on Microsoft Azure MS애저의 기계학습 소개
In this article:
- What is machine learning?
- What is Machine Learning on Microsoft Azure?
- What is predictive analytics?
- Build complete machine learning solutions in the cloud
- Key machine learning terminology and concepts
- Next steps
- 0 Comments
What is machine learning?
기계학습이란?
Machine learning is at work all around you. 기계학습은 주변의 모든 곳에 적용되고 있습니다.
When you shop online, machine learning helps recommend other products based on what you've purchased. 고객이 온라인 쇼핑을 할 때 기계학습은 고객이 구매한 제품을 보고 다른 제품을 추천하기도 합니다.
When your credit card is swiped, machine learning helps the bank do fraud detection and notify you if the transaction seems suspicious. 은행 신용카드가 읽힐 때 기계학습은 부정행위를 탐지하여 거래가 의심스러운 경우 고객에게 알려주기도 합니다.
Machine learning uses predictive models that learn from existing data in order to forecast future behaviors, outcomes, and trends. 기계학습은 장래 행동, 결과 그리고 추세를 예측하기 위하여 기존 데이터로부터 학습하는 예측적 모델을 사용합니다.
What is Machine Learning on Microsoft Azure?
Azure 기계학습이란?
Azure Machine Learning is a powerful cloud-based predictive analytics service that makes it possible to quickly create and deploy analytics solutions.
Azure ML은 분석 솔루션을 신속하게 만들어 설치하게 해주는 강력한 클라우드 기반 예측분석 서비스입니다.
Azure Machine Learning not only provides tools to model predictive analytics, but also provides a fully-managed service you can use to to publish your predictive models as ready-to-consume web services.
Azure ML은 예측분석을 모델링하는 도구를 제공할 뿐만 아니라 예측모델을 즉시 사용가능한 웹 서비스로 게시하는 데 사용할 수 있는 완전 관리형 서비스도 제공합니다.
Azure Machine Learning은 클라우드에서 완전한 예측 분석 솔루션을 생성하기 위한 도구를 제공: 예측 모델을 빠르게 생성, 테스트, 운용 및 관리합니다.
Azure Machine Learning provides tools for creating complete predictive analytics solutions in the cloud: Quickly create, test, operationalize, and manage predictive models.
You do not need to buy any hardware nor manually manage virtual machines.
하드웨어를 구입하거나 가상 컴퓨터를 수동으로 관리할 필요가 없습니다.
Azure ML은 ML의 보편화를 위해 빌드되었습니다.
ML 기술의 빌드 및 배포와 관련된 번거로운 작업이 제거되어 모든 사용자가 ML을 쉽게 사용할 수 있습니다.
브라우저 기반 도구 기계학습 스튜디오를 사용하여 신속하게 ML 워크플로우를 만들고 자동화할 수 있습니다.
수백 개의 기존 ML 라이브러리를 끌어서 놓아 예측 분석 솔루션을 빠르게 시작한 다음 필요에 따라 고유한 사용자 지정 R 및 Python 스크립트를 추가하여 확장할 수 있습니다.
스튜디오는 모든 브라우저에서 작동하며 신속하게 솔루션을 개발하고 반복할 수 있게 해줍니다.
Azure Machine Learning은 ML(기계학습) 프로젝트 수명주기를 가속화하고 관리하기 위한 클라우드 서비스입니다.
ML 전문가, 데이터과학자, 엔지니어는 일상적 워크플로에서 이를 사용하여 모델을 교육 및 배포하고 MLOps(기계학습 작업)를 관리할 수 있습니다.
Machine Learning에서 모델을 생성하거나 PyTorch, TensorFlow 또는 scikit-learn 같은 오픈소스 플랫폼에서 구축된 모델을 사용할 수 있습니다.
MLOps 도구는 모델을 모니터링, 재학습, 재배포하는 데 도움이 됩니다.
Azure Machine Learning is a cloud service for accelerating and managing the machine learning (ML) project lifecycle. ML professionals, data scientists, and engineers can use it in their day-to-day workflows to train and deploy models and manage machine learning operations (MLOps).
You can create a model in Machine Learning or use a model built from an open-source platform, such as PyTorch, TensorFlow, or scikit-learn. MLOps tools help you monitor, retrain, and redeploy models.
Who is Azure Machine Learning for?
Azure Machine Learning은 누구를 위한 것인가요?
기계학습은 조직 내에서 MLOps를 구현하는 개인과 팀이 안전하고 감사 가능한 프로덕션 환경에서 ML 모델을 프로덕션으로 가져오는 데 사용됩니다.
데이터 과학자와 ML 엔지니어는 도구를 사용하여 일상적인 워크플로를 가속화하고 자동화할 수 있습니다. 애플리케이션 개발자는 모델을 애플리케이션이나 서비스에 통합하는 도구를 사용할 수 있습니다. 플랫폼 개발자는 내구성 있는 Azure Resource Manager API가 지원하는 강력한 도구 세트를 사용하여 고급 ML 도구를 구축할 수 있습니다.
Microsoft Azure 클라우드에서 작업하는 기업은 인프라에 대해 익숙한 보안 및 역할 기반 액세스 제어를 사용할 수 있습니다. 보호된 데이터에 대한 액세스를 거부하고 작업을 선택하도록 프로젝트를 설정할 수 있습니다.Azure Machine Learning은 누구를 위한 것인가요?
기계 학습은 조직 내에서 MLOps를 구현하는 개인과 팀이 안전하고 감사 가능한 프로덕션 환경에서 ML 모델을 프로덕션으로 가져오는 데 사용됩니다.
데이터 과학자와 ML 엔지니어는 도구를 사용하여 일상적인 워크플로를 가속화하고 자동화할 수 있습니다. 애플리케이션 개발자는 모델을 애플리케이션이나 서비스에 통합하는 도구를 사용할 수 있습니다. 플랫폼 개발자는 내구성 있는 Azure Resource Manager API가 지원하는 강력한 도구 세트를 사용하여 고급 ML 도구를 구축할 수 있습니다.
Microsoft Azure 클라우드에서 작업하는 기업은 인프라에 대해 익숙한 보안 및 역할 기반 액세스 제어를 사용할 수 있습니다.
보호된 데이터에 대한 액세스를 거부하고 작업을 선택하도록 프로젝트를 설정할 수 있습니다
In this article
- Azure Machine Learning은 누구를 위한 것인가요? Who is Azure Machine Learning for?
- 팀 구성원 모두를 위한 생산성 Productivity for everyone on the team
- 엔터프라이즈 준비 및 보안 Enterprise-readiness and security
- 완전한 솔루션을 위한 Azure 통합 Azure integrations for complete solutions
- ML프로젝트 워크플로 Machine learning project workflow
- 모델 훈련 Train models
- 모델 설치 Deploy models
- MLOps: DevOps for machine learning
Azure Machine Learning은 ML(기계학습) 프로젝트 수명주기를 가속화하고 관리하기 위한 클라우드 서비스입니다. ML 전문가, 데이터과학자, 엔지니어는 일상적 워크플로에서 이를 사용하여 모델을 교육 및 배포하고 MLOps(기계학습 작업)를 관리할 수 있습니다.
Azure Machine Learning is a cloud service for accelerating and managing the machine learning (ML) project lifecycle. ML professionals, data scientists, and engineers can use it in their day-to-day workflows to train and deploy models and manage machine learning operations (MLOps).
Machine Learning에서 모델을 생성하거나 PyTorch, TensorFlow 또는 scikit-learn 같은 오픈소스 플랫폼에서 구축된 모델을 사용할 수 있습니다. MLOps 도구는 모델을 모니터링, 재학습, 재배포하는 데 도움이 됩니다.
You can create a model in Machine Learning or use a model built from an open-source platform, such as PyTorch, TensorFlow, or scikit-learn. MLOps tools help you monitor, retrain, and redeploy models.
Tip
Free trial! If you don't have an Azure subscription, create a free account before you begin. Try the free or paid version of Azure Machine Learning. You get credits to spend on Azure services. After they're used up, you can keep the account and use free Azure services. Your credit card is never charged unless you explicitly change your settings and ask to be charged.
무료 시험판! Azure 구독이 없으면 시작하기 전에 무료 계정을 만드세요. Azure Machine Learning의 무료 또는 유료 버전을 사용해 보세요. Azure 서비스에 사용할 수 있는 크레딧을 받습니다. 모두 사용한 후에도 계정을 유지하고 무료 Azure 서비스를 사용할 수 있습니다. 명시적으로 설정을 변경하고 요금청구를 요청하지 않는 한 신용카드에는 요금이 청구되지 않습니다.
팀 구성원 모두를 위한 생산성
Productivity for everyone on the team
ML 프로젝트에는 빌드 및 유지관리를 위해 다양한 기술을 갖춘 팀이 필요한 경우가 많습니다.
기계학습에는 다음을 수행하는 데 도움이 되는 도구가 있습니다:
ML projects often require a team with a varied skill set to build and maintain. Machine Learning has tools that help enable you to:
- 공유 노트북, 컴퓨팅 리소스, 서버리스 컴퓨팅(미리보기), 데이터 및 환경을 통해 팀과 협업 Collaborate with your team via shared notebooks, compute resources, serverless compute (preview), data, and environments.
- 계보 및 감사규정 준수 요구사항을 충족을 위해 공정성, 설명가능성, 추적 및 감사가능성을 위한 모델을 개발 Develop models for fairness and explainability and tracking and auditability to fulfill lineage and audit compliance requirements.
- ML 모델을 규모에 맞게 빠르고 쉽게 배포하고 MLOps를 통해 효율적으로 관리 및 통제 Deploy ML models quickly and easily at scale, and manage and govern them efficiently with MLOps.
- 내장된 거버넌스, 보안, 규정준수를 통해 어디서나 ML 워크로드를 실행 Run ML workloads anywhere with built-in governance, security, and compliance.
요구사항을 충족하는 교차-호환 플랫폼 도구
Cross-compatible platform tools that meet your needs
ML 팀 모든 구성원은 선호하는 도구를 사용하여 작업을 완료할 수 있습니다. 신속한 실험실행, 초매개변수 조정, 파이프라인 구축, 추론관리 등 무엇을 하든 다음과 같은 친숙한 인터페이스를 사용할 수 있습니다.
Anyone on an ML team can use their preferred tools to get the job done. Whether you're running rapid experiments, hyperparameter-tuning, building pipelines, or managing inferences, you can use familiar interfaces including:
Machine Learning 개발 주기의 나머지 부분에서 모델을 개선하고 다른 사람들과 협력하면서 Machine Learning 스튜디오 UI에서 프로젝트에 대한 자산, 리소스 및 지표를 공유하고 찾을 수 있습니다.
As you're refining the model and collaborating with others throughout the rest of the Machine Learning development cycle, you can share and find assets, resources, and metrics for your projects on the Machine Learning studio UI.
Studio
Machine Learning 스튜디오는 아무것도 설치하지 않고도 프로젝트 유형과 과거 ML 경험 수준에 따라 다양한 작성 경험을 제공합니다.
Machine Learning studio offers multiple authoring experiences depending on the type of project and the level of your past ML experience, without having to install anything.
- Notebooks: 스튜디오에 직접 통합된 관리형 Jupyter 노트북 서버에서 자체 코드를 작성하고 실행 Write and run your own code in managed Jupyter Notebook servers that are directly integrated in the studio.
- Visualize run metrics 실행지표 시각화: 시각화를 통해 실험을 분석하고 최적화 Analyze and optimize your experiments with visualization.
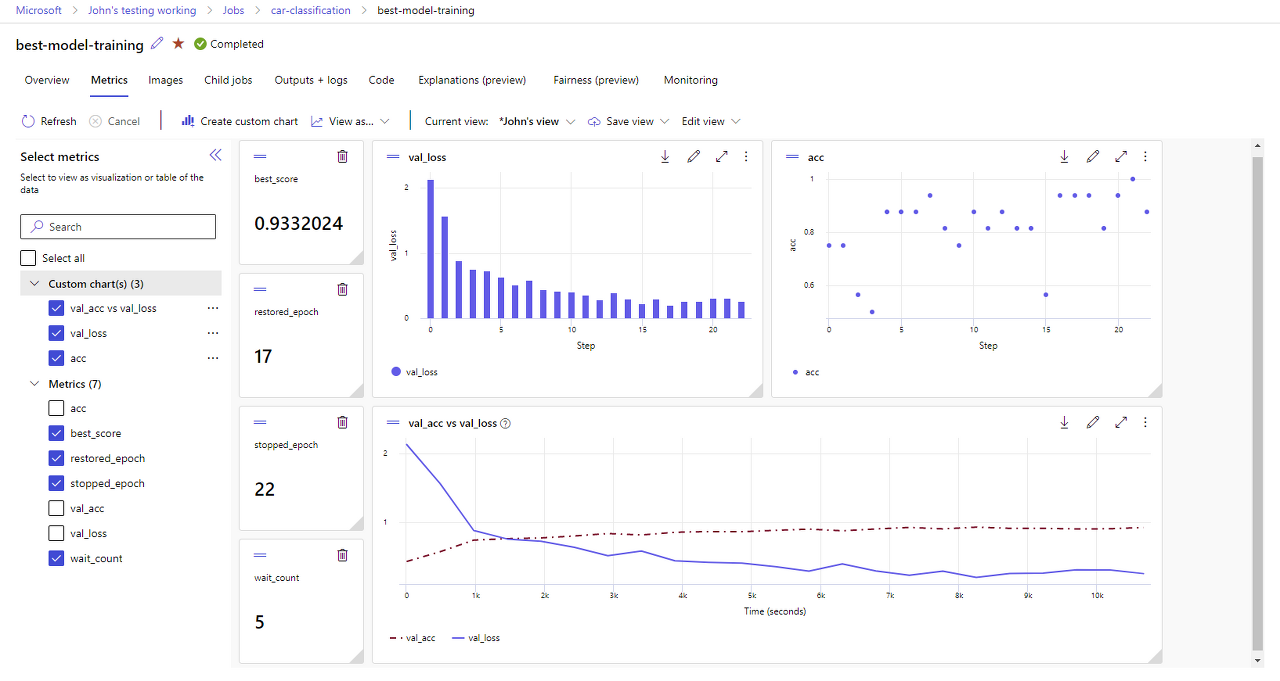
훈련 실행에 대한 지표를 보여주는 스크린샷
- Azure Machine Learning designer 디자이너: 디자이너를 사용하여 코드를 작성하지 않고도 ML 모델을 학습하고 배포. 데이터세트와 구성요소를 드래그앤드롭하여 ML 파이프라인을 생성 Use the designer to train and deploy ML models without writing any code. Drag and drop datasets and components to create ML pipelines.
- Automated machine learning UI: 자동화된 기계학습 UI: 사용하기 쉬운 인터페이스로 자동화된 ML 실험을 만드는 방법 Learn how to create automated ML experiments with an easy-to-use interface.
- Data labeling 데이터 라벨링: 기계학습 데이터라벨링을 사용하여 이미지라벨링 또는 텍스트라벨링 프로젝트를 효율적으로 조정 Use Machine Learning data labeling to efficiently coordinate image labeling or text labeling projects.
Enterprise-readiness and security
엔터프라이즈 준비 및 보안
Machine Learning은 Azure 클라우드 플랫폼과 통합되어 ML 프로젝트에 보안을 추가합니다. Machine Learning integrates with the Azure cloud platform to add security to ML projects.
보안 통합에는 다음이 포함됩니다: Security integrations include:
- 네트워크 보안그룹이 있는 Azure 가상네트워크 Azure Virtual Networks with network security groups.
- 스토리지 계정에 대한 액세스 정보 같은 보안비밀을 저장할 수 있는 Azure Key Vault Azure Key Vault, where you can save security secrets, such as access information for storage accounts.
- 가상네트워크 뒤에 설정된 Azure Container Registry Azure Container Registry set up behind a virtual network.
자세한 내용은 튜토리얼: 안전한 작업공간 설정을 참조하세요. For more information, see Tutorial: Set up a secure workspace.
Azure integrations for complete solutions
완전한 솔루션을 위한 Azure 통합
Azure 서비스와의 기타 통합은 ML 프로젝트를 처음부터 끝까지 지원합니다. 여기에는 다음이 포함됩니다. Other integrations with Azure services support an ML project from end to end. They include:
- Spark를 사용하여 데이터를 처리하고 스트리밍하는 데 사용되는 Azure Synapse Analytics. Azure Synapse Analytics, which is used to process and stream data with Spark.
- Kubernetes 환경에서 Azure 서비스를 실행할 수 있는 Azure Arc. Azure Arc, where you can run Azure services in a Kubernetes environment.
- Azure SQL Database 및 Azure Blob Storage 같은 스토리지 및 데이터베이스 옵션 Storage and database options, such as Azure SQL Database and Azure Blob Storage.
- ML 기반 앱을 배포하고 관리하는 데 사용할 수 있는 Azure App Service. Azure App Service, which you can use to deploy and manage ML-powered apps.
- 조직 전체에서 데이터 자산을 검색하고 카탈로그화할 수 있는 Microsoft Purview. Microsoft Purview, which allows you to discover and catalog data assets across your organization.
Important
Machine Learning은 배포하는 지역 외부에 데이터를 저장하거나 처리하지 않습니다. Machine Learning doesn't store or process your data outside of the region where you deploy.
Machine learning project workflow
일반적으로 모델은 목적과 목표가 있는 프로젝트의 일부로 개발됩니다. 프로젝트에는 종종 2명 이상 사람이 참여합니다. 데이터, 알고리즘, 모델을 실험할 때 개발은 반복됩니다. Typically, models are developed as part of a project with an objective and goals. Projects often involve more than one person. When you experiment with data, algorithms, and models, development is iterative.
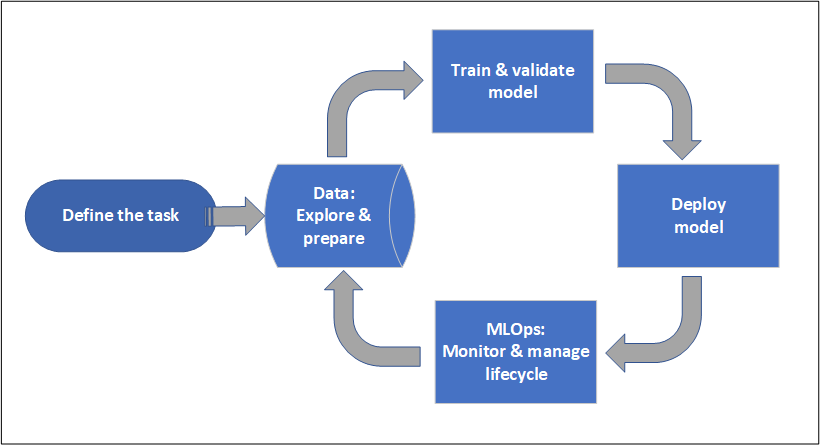
프로젝트 라이프사이클 Project lifecycle
프로젝트 수명주기는 프로젝트마다 다를 수 있지만 대개 이 다이어그램과 같습니다. The project lifecycle can vary by project, but it often looks like this diagram.
작업공간은 프로젝트를 구성하고 공통 목표를 위해 노력하는 많은 사용자의 협업을 허용합니다. 작업 공간의 사용자는 스튜디오 사용자 인터페이스에서 실험을 통해 얻은 실행 결과를 쉽게 공유할 수 있습니다. 또는 환경 및 스토리지 참조 같은 작업에 버전이 지정된 자산을 사용할 수 있습니다.
자세한 내용은 Azure Machine Learning 작업 영역 관리를 참조하세요.
프로젝트 운영 준비가 완료되면 사용자 작업이 ML 파이프라인에서 자동화되고 일정이나 HTTPS 요청에 따라 트리거될 수 있습니다.
실시간 및 일괄 배포 모두를 위해 관리형 추론 솔루션에 모델을 배포할 수 있으며, 모델 배포에 일반적으로 필요한 인프라 관리를 추상화할 수 있습니다.
A workspace organizes a project and allows for collaboration for many users all working toward a common objective. Users in a workspace can easily share the results of their runs from experimentation in the studio user interface. Or they can use versioned assets for jobs like environments and storage references.
For more information, see Manage Azure Machine Learning workspaces.
When a project is ready for operationalization, users' work can be automated in an ML pipeline and triggered on a schedule or HTTPS request.
You can deploy models to the managed inferencing solution, for both real-time and batch deployments, abstracting away the infrastructure management typically required for deploying models.
Train models
기계학습에서는 클라우드에서 훈련 스크립트를 실행하거나 처음부터 모델을 구축할 수 있습니다. 고객은 클라우드에서 운영할 수 있도록 오픈 소스 프레임워크에서 구축하고 교육한 모델을 가져오는 경우가 많습니다. In Machine Learning, you can run your training script in the cloud or build a model from scratch. Customers often bring models they've built and trained in open-source frameworks so that they can operationalize them in the cloud.
개방성과 상호운용성 Open and interoperable
데이터과학자는 다음 같은 일반적 Python 프레임워크에서 만든 모델을 기계학습에서 사용할 수 있습니다. Data scientists can use models in Machine Learning that they've created in common Python frameworks, such as:
- PyTorch
- TensorFlow
- scikit-learn
- XGBoost
- LightGBM
다른 언어와 프레임워크도 지원됩니다: Other languages and frameworks are also supported:
- R
- .NET
자세한 내용은 Azure Machine Learning과 오픈소스 통합을 참조하세요. For more information, see Open-source integration with Azure Machine Learning.
자동화된 기능화 및 알고리즘 선택 Automated featurization and algorithm selection
반복적이고 시간이 많이 걸리는 프로세스에서 기존 ML의 데이터과학자는 사전 경험과 직관을 사용하여 훈련에 적합한 데이터 기능화 및 알고리즘을 선택합니다. 자동화된 ML (AutoML)은 이 프로세스의 속도를 높입니다. Machine Learning 스튜디오 UI 또는 Python SDK를 통해 사용할 수 있습니다. In a repetitive, time-consuming process, in classical ML, data scientists use prior experience and intuition to select the right data featurization and algorithm for training. Automated ML (AutoML) speeds this process. You can use it through the Machine Learning studio UI or the Python SDK.
For more information, see What is automated machine learning?.
자세한 내용은 자동화된 기계 학습이란 무엇입니까?를 참조하세요.
초매개변수 최적화 Hyperparameter optimization
하이퍼파라미터 최적화 또는 하이퍼파라미터 튜닝은 지루한 작업이 될 수 있습니다. 기계학습은 작업 정의를 거의 수정하지 않고도 임의의 매개변수화된 명령에 대해 이 작업을 자동화할 수 있습니다. 결과는 스튜디오에서 시각화됩니다. Hyperparameter optimization, or hyperparameter tuning, can be a tedious task. Machine Learning can automate this task for arbitrary parameterized commands with little modification to your job definition. Results are visualized in the studio.
For more information, see Tune hyperparameters.
자세한 내용은 하이퍼파라미터 조정을 참조하세요.
다중노드분산 훈련 Multinode distributed training
다중노드분산 교육을 통해 딥러닝 및 때로는 기존 ML 교육 작업에 대한 교육 효율성을 대폭 향상할 수 있습니다. Machine Learning 컴퓨팅 클러스터 및 서버리스 컴퓨팅(미리보기)은 최신 GPU 옵션을 제공합니다. Azure Machine Learning Kubernetes, Machine Learning 컴퓨팅 클러스터 및 서버리스 컴퓨팅(미리보기)을 통해 지원되는 프레임워크는 다음과 같습니다. Efficiency of training for deep learning and sometimes classical ML training jobs can be drastically improved via multinode distributed training. Machine Learning compute clusters and serverless compute (preview) offer the latest GPU options.
Frameworks supported via Azure Machine Learning Kubernetes, Machine Learning compute clusters, and serverless compute (preview) include:
- PyTorch
- TensorFlow
- MPI
Horovod 또는 사용자 지정 다중 노드 논리에 MPI 배포를 사용할 수 있습니다. Apache Spark는 Azure Synapse Analytics Spark 클러스터를 사용하는 서버리스 Spark 컴퓨팅 및 연결된 Synapse Spark 풀을 통해 지원됩니다. You can use MPI distribution for Horovod or custom multinode logic. Apache Spark is supported via serverless Spark compute and attached Synapse Spark pool that use Azure Synapse Analytics Spark clusters.
For more information, see Distributed training with Azure Machine Learning. 자세한 내용은 Azure Machine Learning을 사용한 분산 교육을 참조하세요.
당혹스러울 정도로 병렬 훈련 Embarrassingly parallel training
ML 프로젝트를 확장하려면 당황스러울 정도로 병렬 모델 교육을 확장해야 할 수도 있습니다. 이 패턴은 모델이 여러 매장에 대해 학습될 수 있는 수요 예측과 같은 시나리오에서 일반적입니다. Scaling an ML project might require scaling embarrassingly parallel model training. This pattern is common for scenarios like forecasting demand, where a model might be trained for many stores.
Deploy models
모델 배포
모델을 프로덕션 환경으로 가져오기 위해 모델이 배포됩니다. Machine Learning 관리 엔드포인트는 배치 또는 실시간(온라인) 모델 채점(추론)에 필요한 인프라를 추상화합니다. To bring a model into production, it's deployed. The Machine Learning managed endpoints abstract the required infrastructure for both batch or real-time (online) model scoring (inferencing).
실시간 및 일괄 채점 (추론) Real-time and batch scoring (inferencing)
일괄 채점 또는 일괄 추론에는 데이터에 대한 참조를 사용하여 엔드포인트를 호출하는 작업이 포함됩니다. 배치 엔드포인트는 작업을 비동기식으로 실행하여 컴퓨팅 클러스터에서 데이터를 병렬로 처리하고 추가 분석을 위해 데이터를 저장합니다. Batch scoring, or batch inferencing, involves invoking an endpoint with a reference to data. The batch endpoint runs jobs asynchronously to process data in parallel on compute clusters and store the data for further analysis.
실시간 채점 또는 온라인 추론에는 하나 이상의 모델 배포로 엔드포인트를 호출하고 HTTPS를 통해 거의 실시간으로 응답을 받는 것이 포함됩니다. 트래픽을 여러 배포로 분할할 수 있으므로 처음에는 일정량의 트래픽을 전환하고 새 모델에 대한 신뢰도가 확립된 후에 트래픽을 늘려 새 모델 버전을 테스트할 수 있습니다. Real-time scoring, or online inferencing, involves invoking an endpoint with one or more model deployments and receiving a response in near real time via HTTPS. Traffic can be split across multiple deployments, allowing for testing new model versions by diverting some amount of traffic initially and increasing after confidence in the new model is established.
For more information, see:
자세한 내용은 다음을 참조하세요.
- 실시간 관리형 엔드포인트있는 모델 배포 Deploy a model with a real-time managed endpoint
- 채점을 위해 배치 엔드포인트 사용 Use batch endpoints for scoring
MLOps: DevOps for machine learning 기계학습을 위한 DevOps
MLOps로도 불리는 ML모델용 DevOps는 프로덕션용모델을 개발하는 프로세스입니다. 훈련부터 배포까지 모델의 수명주기는 재현할 수 없는 경우 감사가 가능해야 합니다. DevOps for ML models, often called MLOps, is a process for developing models for production. A model's lifecycle from training to deployment must be auditable if not reproducible.
- ML model lifecycle
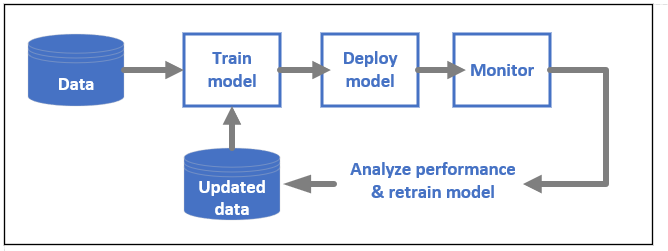
기계학습 모델 수명 주기 * MLOps를 보여주는 다이어그램.
Azure Machine Learning의 MLOps에 대해 자세히 알아보세요. Learn more about MLOps in Azure Machine Learning.
MLOPs를 지원하는 통합 Integrations enabling MLOPs
기계학습은 모델 수명주기를 염두에 두고 구축되었습니다.
특정 커밋 및 환경까지 모델 수명주기를 감사할 수 있습니다.
Machine Learning is built with the model lifecycle in mind. You can audit the model lifecycle down to a specific commit and environment.
MLOps를 활성화하는 몇 가지 주요 기능은 다음과 같습니다: Some key features enabling MLOps include:
- git integration.
- MLflow integration.
- Machine learning pipeline scheduling.
- 사용자 지정 트리거를 위한 Azure Event Grid 통합 Azure Event Grid integration for custom triggers.
- GitHub Actions 또는 Azure DevOps 같은 CI/CD 도구를 사용하기 쉬움 Ease of use with CI/CD tools like GitHub Actions or Azure DevOps.
기계학습에는 모니터링 및 감사 기능도 포함되어 있습니다 Machine Learning also includes features for monitoring and auditing:
- 코드 스냅샷, 로그, 기타 출력과 같은 작업 아티팩트 Job artifacts, such as code snapshots, logs, and other outputs.
- 컨테이너, 데이터, 컴퓨팅 리소스 등 작업과 자산 간의 계보 Lineage between jobs and assets, such as containers, data, and compute resources.
Next steps
Azure Machine Learning 사용을 시작 Start using Azure Machine Learning:
- Azure Machine Learning 작업영역 설정 Set up an Azure Machine Learning workspace
- Tutorial: 첫 번째 기계학습 프로젝트 빌드 Build a first machine learning project
- 훈련작업 실행 Run training jobs
What is predictive analytics? 예측적 분석이란?
Predictive analytics uses various statistical techniques - in this case, machine learning - to analyze collected or current data for patterns or trends in order to forecast future events.
예측적 분석은 미래 사건을 예측하기 위하여, 수집되거나 현행 데이터의 패턴 또는 추세를 분석하기 위하여 다양한 통계기법(이 경우, ML)을 사용합니다.
Azure Machine Learning is a particularly powerful way to do predictive analytics:
애저ML은 특히 예측적 분석에 강한 도구입니다.
You can work from a ready-to-use library of algorithms, create models on an internet-connected PC without purchasing additional equipment or infrastructure, and deploy your predictive solution quickly. 미리 준비된 알고리즘 라이브러리로 작업할 수 있고, 장비 또는 인프라스트럭쳐를 추가로 구매하지 않고도 인터넷에 연결된 PC에서 모델을 만들어서 신속하게 예측 솔루션을 설치할 수 있습니다
You can also find ready-to-use examples and solutions in the Mirosoft Azure Marketplace or Machine Learning Gallery.
Build complete machine learning solutions in the cloud 클라우드에 완벽한 기계학습 솔루션 구축하기
Azure Machine Learning has everything you need to create predictive analytics solutions in the cloud from a large algorithm library, to a studio for building models, to an easy way to deploy your model as a web service.
Machine Learning Studio: Create predictive models
기계학습 스튜디오: 예측적 모델 만들기
Create predictive models in Machine Learning Studio, a browser-based tool, by dragging, dropping, and connecting modules.
브라우저 기반 도구인 ML 스튜디오에서, 모듈을 드래깅, 드로핑 그리고 연결하여 예측모델을 만들어 보세요.

- Use a large library of Machine Learning algorithms and modules in Machine Learning Studio to jump-start your predictive models.
ML스튜디오에서 ML알고리즘 및 모듈의 대형 라이브러리를 사용해서 예측 모델을 시작하세요.
Choose from a library of sample experiments, R and Python packages, and best-in-class algorithms from Microsoft businesses like Xbox and Bing.
샘플 실험, R 및 파이썬 패키지, 그리고 최고의 알고리즘
Extend Studio modules with your own custom R and Python scripts.
· In Machine Learning Community Gallery, you can get started with Azure Machine Learning and learn from others in the community.
ML 커뮤니티 갤러리를 통해 애저ML을 시작할 수 있고 커뮤니티의 다른 사용자로부터 배울 수 있습니다.
Try experiments authored by others, ask questions or post comments about experiments, or publish your own experiments.
다른 사람들이 만든 실험을 시도해볼 수 있고, 실험에 관해 질문하거나 의견을 포스트할 수 있으며, 또는 당신의 실험을 게시할 수 있습니다.
You can also share links to experiments via social networks such as LinkedIn and Twitter. 갤러리에서 실험에 대한 질문을 하거나 의견을 게시할 수 있으며, 또는 고유한 실험을 게시할 수도 있습니다. LinkedIn 및 Twitter와 같은 소셜 채널을 통해 흥미로운 실험에 대한 링크를 공유할 수 있습니다. 갤러리는 사용자가 Azure 기계 학습을 시작하고 커뮤니티의 다른 사용자로부터 배울 수 있는 효율적인 방법입니다.
쉽게 웹 서비스를 검색 및 만들고, API를 통해 모델을 학습 및 다시 학습하고, 끝점을 관리하고, 고객별로 웹 서비스를 확장하고, 서비스 모니터링 및 디버깅을 위해 진단을 구성할 수 있습니다.
최신 기능에는 다음이 포함되었습니다.
· numpy, scipy, panda 또는 scikit-learn과 같은 대규모 라이브러리 에코시스템을 사용하여 구성 가능한 사용자 지정 R 모듈을 만들고, 고유한 학습/예측 R 스크립트를 통합하고, Python 스크립트를 추가하는 기능. 이제 개수로 학습을 사용하여 테라바이트 데이터를 학습하고, PCA 또는 단일 클래스 SVM을 이상 검색에 사용하고, 익숙한 SQLite를 사용하여 쉽게 데이터를 수정, 필터링 및 정리할 수 있습니다.

Operationalize predictive analytics solutions: Purchase web services or publish your own
예측적 분석 솔루션 가동시키기: 웹서비스 구매 또는 개발된 것을 게시하기
- Purchase ready-to-consume web services from Mirosoft Azure Marketplace, such as Recommendations, Text Analytics, and Anomaly Detection.
- Operationalize your predictive analytics models:
Key machine learning terminology and concepts
핵심 기계학습 용어 및 개념
Data exploration, descriptive analytics, and predictive analytics 데이터 탐험, 서술적 분석, 그리고 예측적 분석
Data exploration is the process of gathering information about a large and often unstructured data set in order find characteristics for focused analysis. Data mining refers to automated data exploration.
Descriptive analytics is the process of analyzing a data set in order to summarize what happened. The vast majority of business analytics - such as sales reports, web metrics, and social networks analysis - are descriptive.
Predictive analytics is the process of building models from historical or current data in order to forecast future outcomes.
Supervised and unsupervised learning 지도학습 및 자율학습
Supervised learning algorithms are trained with labeled data - in other words, data comprised of examples of the answers wanted. For instance, a model that identifies fraudulent credit card use would be trained from a data set in which data points indicating known fraudulent and valid charges were labeled. Most machine learning is supervised.
Unsupervised learning is used on data with no labels, and the goal is to find relationships in the data. For instance, you might want to find groupings of customer demographics with similar buying habits.
Model training and evaluation 모델 훈련 및 평가
A machine learning model is an abstraction of the question you are trying to answer or the outcome you want to predict. Models are trained and evaluated from existing data.
In Azure Machine Learning, a model is built from an algorithm module that processes training data and functional modules, such as a scoring module.
In supervised learning, if you're training a fraud detection model, you'll use a set of transactions that are labeled as either fraudulent or valid. You'll split your data set randomly, and use part to train the model and part to test or evaluate the model.
Once you have a trained model, evaluate the model using the remaining test data. You use data you already know the outcomes for, so that you can tell whether your model predicts accurately.
Other common machine learning terms
기타 공통 기계학습 용어들
- algorithm: A self-contained set of rules used to solve problems through data processing, calculation, or automated reasoning.
- categorical data: Data that is organized by categories and that can be divided into groups. For example a categorical data set for autos could specify year, make, model, and price.
- classification: A model for organizing data points into categories based on a data set for which category groupings are already known.
- feature engineering: The process of extracting or selecting features related to a data set in order to enhance the data set and improve outcomes. For instance, airfare data could be enhanced by days of the week and holidays. See Feature selection and engineering in Azure Machine Learning.
- module: A functional element in a Machine Learning Studio model, such as the Enter Data module which enables entering and editing small data sets. An algorithm is also a type of module in Machine Learning Studio.
- model: For supervised learning, a model is the product of a machine learning experiment comprised of a training data set, an algorithm module, and functional modules, such as a Score Model module.
- numerical data: Data that has meaning as measurements (continuous data) or counts (discrete data). Also referred to as quantitative data.
- partition: The method by which you divide data into samples. See Partition and Sample for more information.
- prediction: A prediction is a forecast of a value or values from a machine learning model. You might also see the term "predicted score"; however, predicted scores are not the final output of a model. An evaluation of the model follows the score.
- regression: A model for predicting a continuous value based on independent variables, such as predicting the price of a car based on its year and make.
- score: A predicted value generated from a trained classification or regression model, using the Score Model module in Machine Learning Studio. Classification models also return a score for the probability of the predicted value. Once you've generated scores from a model, you can evaluate the model's accuracy using the Evaluate Model module.
- sample: A part of a data set intended to be representative of the whole. Samples can be selected randomly or based on specific features of the data set.
You can learn the basics of predictive analytics and machine learning using a step-by-step tutorial and by building on samples.
· Azure 구독을 통해 마켓플레이스 앱을 구매하고 Azure 마켓플레이스에서 직접 권장 사항, 텍스트 분석 및 이상 검색에 완성된 웹 서비스를 사용할 수 있습니다.
· 원시 데이터에서 사용 가능한 웹 서비스에 이르기까지 클라우드 기반 데이터 과학으로 향하는 길을 안내하는 데이터 과학 여행을 위한 단계별 가이드. Azure 기계 학습과 함께 iPython Notebook 및 Visual Studio용 Python Tools와 같은 인기 있는 도구를 사용하는 기능이 추가되었습니다.
단계별 자습서 및 샘플을 기반으로 빌드를 사용하여 예측 분석 및 기계 학습의 기본 사항을 알아볼 수 있습니다. Azure 구독이나 신용 카드가 없어도 스튜디오에서 실험을 시도할 때 기계 학습을 사용할 수 있습니다.
Azure Machine Learning Frequently Asked Questions (FAQ): Billing, capabilties, limitations, and support
By pablissima Last updated: 05/07/2015
Contributors Edit on GitHub
In this article:
- General questions
- Billing questions
- Machine Learning Studio questions
- Web service
- Scalability
- Security and availability
- Azure Marketplace
- Support and training
- 3 Comments
This FAQ is answers questions about the Azure Machine Learning, a cloud service for predictive modeling and operationalizing solutions through web services. This FAQ covers questions about using the service, including the billing model, capabilities, limitations, and support.
What is Azure Machine Learning?
Azure Machine Learning is a fully managed service that you can use to create, test, operate, and manage predictive analytic solutions in the cloud. With only a browser, you can sign-in, upload data, and immediately start machine learning experiments. Drag-and-drop predictive modeling, a large pallet of modules, and a library of starting templates makes common machine learning tasks simple and quick. For more information, see the Azure Machine Learning service overview. For a machine learning introduction covering key terminology and concepts, see Introduction to Azure Machine Learning.
Try Azure Machine Learning for free
No credit card or Azure subscription needed. Get started now >
What is Machine Learning Studio?
Machine Learning Studio is a workbench environment you access through a web browser. Machine Learning Studio hosts a pallet of modules with a visual composition interface that enables you to build an end-to-end, data-science workflow in the form of an experiment.
For more information about the Machine Learning Studio, see What is Machine Learning Studio
What is the Machine Learning API service?
The Machine Learning API service enables you to deploy predictive models built in Machine Learning Studio as scalable, fault-tolerant, web services. The web services created by the Machine Learning API service are REST APIs that provide an interface for communication between external applications and your predictive analytics models.
See Connect to a Machine Learning web service for more information.
How does Machine Learning billing work?
For billing and pricing information, see Machine Learning Pricing.
Does Machine Learning have a free trial?
When you sign up for an Azure free trial, you can try any Azure services for a month. To learn more about Azure free trial, visit Azure Free Trial FAQ.
Machine Learning Studio questions
Is there version control or Git integration for experiment graphs?
No, however each time an experiment is run that version of the graph is kept and cannot be modified by other users.
Importing and exporting data for Machine Learning
What data sources does Machine Learning support?
Data can be loaded into Machine Learning Studio in one of two ways: by uploading local files as a dataset or by using a reader module to import data. Local files can be uploaded by adding new datasets in Machine Learning Studio. See Import training data into Machine Learning Studio to learn more about supported file formats.
How large can the data set be for my modules?
Modules in Machine Learning Studio support datasets of up to 10 GB of dense numerical data for common use cases. If a module takes more than one input, the 10 GB is the total of all input sizes. You can also sample larger datasets via Hive or Azure SQL Database queries, or by Learning by Counts pre-processing, before ingestion.
The following types of data can expand into larger datasets during feature normalization, and are limited to less than 10 GB:
- Sparse
- Categorical
- Strings
- Binary data
The following modules are limited to datasets less than 10GB:
- Recommender modules
- SMOTE module
- Scripting modules: R, Python, SQL
- Modules where the output data size can be larger than input data size, such as Join or Feature Hashing.
- Cross-validation, Sweep Parameters, Ordinal Regression and One-vs-All Multiclass, when number of iterations is very large.
For datasets larger than a few GB, you should upload data to Azure storage or Azure SQL Database or use HDInsight, rather than directly uploading from local file.
What are the limits for data upload?
For datasets larger than a couple GB, upload data to Azure storage or Azure SQL Database or use HDInsight, rather than directly uploading from local file.
Can I read data from Amazon S3?
If you have a small amount of data and want to expose it via an http URL, then you can use the Reader module. For any larger amounts of data to transfer it to Azure Storage first and then use the Reader module to bring it into your experiment.
Is there a built-in image input capability?
You can learn about image input capability in the Image Reader reference.
Modules
The algorithm, data source, data format, or data transformation operation I am looking for isn't in Azure ML Studio, what are my options?
You can visit the user feedback forum to see features requests that we are tracking. Add your vote to this request if a capability you are looking for has already been requested. If the capability you are looking for does not exist, create a new request. You can view the status of your request in this forum too. We track this list closely and update the status of feature availability frequently. In addition with the built-in support for R and Python, custom transformations can be created as needed.
Can I bring my existing code into ML Studio?
Yes, you can bring your existing R code in ML Studio and run it in the same experiment with Azure Machine Learning-provided learners and publish this as a web service via Azure Machine Learning. See Extend your experiment with R .
Is it possible to use something like PMML to define a model?
No, that is not supported, however custom R and Python code can be used to define a module.
Is there an ability to visualize data (beyond R visualizations) interactively within the experiment?
By clicking on the output of a module you can visualize the data and get statistics.
When previewing results or data in the browser, the number of rows and columns is limited, why?
Since the data is being transmitted to the browser and may be large, the data size is limited to prevent slowing down the ML studio. It is better to download the data/result and use Excel or another tool to visualize the entire data.
What existing algorithms are supported in Machine Learning Studio?
Machine Learning Studio provides state of the art algorithms, such as Scalable Boosted Decision trees, Bayesian Recommendation systems, Deep Neural Networks, and Decision Jungles developed at Microsoft Research. Scalable open-source machine learning packages like Vowpal Wabbit are also included. Machine Learning Studio supports machine learning algorithms for multiclass and binary classification, regression, and clustering. See the complete list of Machine Learning Modules.
Do you automatically suggest the right Machine Learning algorithm to use for my data?
No, however there are a number of ways in Machine Learning Studio to compare the results of each algorithm to determine the right one for your problem.
Do you have any guidelines on picking one algorithm over another for the provided algorithms? See How to choose an algorithm .
Are the provided algorithms written in R or Python?
No, these algorithms are mostly written in compiled languages to provide higher performance.
Are any details of the algorithms provided?
The documentation provides some information about the algorithms, and the parameters provided for tuning are described to optimize the algorithm for your use.
Is there any support for online learning?
No, currently only programmatic retraining is supported.
Can I visualize the layers of a Neural Net Model using the built-in Module?
No.
Can I create my own modules in C# or some other language?
Currently new custom modules can only be created in R.
What R packages are available in Machine Learning Studio?
Machine Learning Studio supports 400+ R packages today, and this list is constantly growing. See Extend your experiment with R to learn how to get a list of supported R packages. If the package you want is not in this list, provide the name of package at user feedback forum.
Is it possible to build a custom R module?
Yes, see Author custom R modules in Azure Machine Learning for more information.
Is there a REPL environment for R?
No, there is no REPL environment for R in the studio.
Is it possible to build a custom Python module?
Not currently, but with the standard Python module or a set of them the same result can be achieved.
Is there a REPL environment for Python?
No, there is no REPL environment for Python in the studio.
Retrainining Models Programmatically
How do I Retrain AzureML Models programmaticlly? Use the Retraining APIs. Sample code is available here.
Can I deploy the model locally or in an application without an internet connection? No.
Is there a baseline latency that is expected for all web services?
See the Azure subscription limits
When would I want to run my predictive model as a Batch Execution service versus a Request Response service?
The Request Response service (RRS) is a low-latency, high-scale web service that is used to provide an interface to stateless models that are created and published from the experimentation environment. The Batch Execution service (BES) is a service for asynchronously scoring a batch of data records. The input for BES is similar to data input used in RRS. The main difference is that BES reads a block of records from a variety of sources, such as the Blob service and Table service in Azure, Azure SQL Database, HDInsight (hive query), and HTTP sources. For more information, see How to consume Machine Learning web services.
How do I update the model for the deployed web service?
Updating a predictive model for an already deployed service is as simple as modifying and re-running the experiment used to author and save the trained model. Once you have new version of the trained model available, ML Studio will ask you if you want to update your staging web service. After the update is applied to the staging web service, the same update will become available for you to apply to the production web service as well. See Publish a Machine Learning web service for details on how to update a deployed web service.
How do I monitor my Web service deployed in production?
Once a predictive model has been put into production, you can monitor it from the Azure portal. Each deployed service has its own dashboard, where you can see monitoring information for that service.
Is there a place where I can see the output of my RRS/BES?
Yes, you must provide a blob storage location and the output of the RRS/BES will be placed there.
What is the scalability of the web service?
Currently, the maximum is 20 concurrent requests per end point, though it can scale to 80 end points. This translates to 4,800 concurrent request if we use every resource (300 workers).
Are R jobs spread across nodes?
No.
How much data can I train on?
Modules in Machine Learning Studio support datasets of up to 10 GB of dense numerical data for common use cases. If a module takes more than one input, the 10 GB is the total of all input sizes. You can also sample larger datasets via Hive or Azure SQL Database queries, or by Learning by Counts pre-processing, before ingestion.
The following types of data can expand into larger datasets during feature normalization, and are limited to less than 10 GB:
- Sparse
- Categorical
- Strings
- Binary data
The following modules are limited to datasets less than 10GB:
- Recommender modules
- SMOTE module
- Scripting modules: R, Python, SQL
- Modules where the output data size can be larger than input data size, such as Join or Feature Hashing.
- Cross-validation, Sweep Parameters, Ordinal Regression and One-vs-All Multiclass, when number of iterations is very large.
For datasets larger than a few GB, you should upload data to Azure storage or Azure SQL Database or use HDInsight, rather than directly uploading from local file.
Are there any vector size limitations?
Rows and columns are each limited to the .NET limitation of Max Int: 2,147,483,647.
Can the VM size that this is being run on be adjusted?
No.
Who has access to the http end point for the web service deployed in production by default? How do I restrict access to the end point?
Once a predictive model has been put into production, the Azure Portal lists the URL for the deployed web services. Staging service URLs are accessible from the Machine Learning Studio Environment in the web services section; Production service URLs are accessible from Azure Portal, in the Machine Learning section. Access keys are provided for both Staging and Production web services from the web service dashboard in the Machine Learning Studio and Azure portal environments, respectively. Access keys are needed to make calls to the web service in production and staging. For more information, see Connect to a Machine Learning web service.
What happens if my Storage Account cannot be found?
Machine Learning Studio relies on a user supplied Azure Storage Account to save intermediary data when executing the workflow. This Storage Account is provided to Machine Learning Studio at the time a workspace is created. After the workspace is created, if the Storage Account is deleted and can no longer be found, that workspace will stop functioning and all experiments in that workspace will fail.
If you accidentally deleted the Storage Account, the only way to recover from it is to recreate that Storage Account with the exact same name in the exact same Region as the deleted one. After that, please re-sync the Access Key.
What happens if my Storage Account Access Key is out of sync? Machine Learning Studio relies on a user supplied Azure Storage Account to save intermediary data when executing the workflow. This Storage Account is provided to Machine Learning Studio at the time a workspace is created and the Access Keys are associated with that workspace. After the workspace is created, if the Access keys are changed, that workspace can no longer access the Storage Account, and it will stop functioning and all experiments in that workspace will fail.
If you have changed Storage Account Access Keys, please ensure to resync the Access Keys in the workspace setting in the Azure portal
See the FAQ for publishing and using apps in the Machine Learning Marketplace
Where can I get training for Azure ML?
Azure Machine Learning Documentation Center hosts video tutorials as well as how-to guides. These step-by-step guides provide an introduction to the services and walk through the data science life cycle of importing data, cleaning data, building predictive models and deploying them in production with Azure ML.
We will be adding new material to Machine Learning Center on an ongoing basis. You can submit requests for additional learning material on Machine Learning Center at user feedback forum.
You can also find training at Microsoft Virtual Academy
How do I get support for Azure Machine Learning?
To get technical support for Azure Machine Learning, go to Azure Support select Machine Learning.
Azure Machine Learning also has a community forum on MSDN, where you can ask Azure ML related questions. The forum is monitored by the Azure ML team. Visit Azure Forum.
Microsoft Azure 기계 학습 FAQ
By mayast업데이트: 02-17-2015
일반
1. Microsoft Azure 기계 학습이란 무엇입니까?
Microsoft Azure 기계 학습은 완벽하게 관리되는 서비스로, 이 서비스를 통해 클라우드에 예측 분석 솔루션을 만들고, 테스트하고, 운용 가능하게 하고, 관리할 수 있습니다. 이제 브라우저를 사용하여 Azure 기계 학습에 등록하고 데이터를 업로드하고 즉시 기계 학습 실험을 시작할 수 있습니다. 시각적 컴퍼지션, 모듈의 대형 팔레트 및 시작 템플릿의 라이브러리를 활용하면 일반적인 기계 학습 작업을 간단히, 빠르게 수행할 수 있습니다. 모델을 웹 서비스로 손쉽게 전환할 수 있습니다. 몇 번의 클릭만으로 기계 학습 스튜디오의 예측 모델 빌드를, 사용자 지정 변환 논리 및 정교한 기계 학습 모델을 캡슐화하는 공개 REST API로 전환할 수 있습니다.
2. Azure 기계 학습 스튜디오란 무엇입니까?
Azure 기계 학습 스튜디오는 웹 브라우저를 통해 액세스할 수 있는 워크벤치 환경입니다. 기계 학습 스튜디오는 실험 형태의 전체 데이터 과학 워크플로를 구성할 수 있는 시각적 컴퍼지션 인터페이스와 함께 모듈 팔레트를 호스트합니다. 예측 모델을 빌드하고 점수를 계산하고 평가할 수 있는 데이터 수집, 변환, 기능 선택을 위한 모듈도 있습니다. Bing 및 Xbox의 기계 학습을 지원하는 가장 발전한 알고리즘 중 일부가 기계 학습 스튜디오에 기본 제공됩니다. Vowpal Wabbit과 같은 확장 가능한 오픈 소스 기계 학습 패키지도 포함되어 있습니다. 기계 학습 스튜디오는 R을 지원하므로 기존 R 코드를 가져와 실험에 통합할 수 있습니다. 기계 학습 스튜디오를 통해 R 코드와 이러한 알고리즘을 결합하여 예측 모델을 빌드할 수 있습니다. 기계 학습 스튜디오에서는 실험을 보고 수정할 수 있는 작업 영역으로 팀으로 초대할 수 있으므로 쉽게 협업할 수 있습니다.
3. Azure 기계 학습 API 서비스란 무엇입니까?
기계 학습 API 서비스를 통해 기계 학습 스튜디오에 기본 제공되는 예측 모델을 확장 가능한 내결함성 웹 서비스로 배포할 수 있습니다. 기계 학습 API 서비스를 통해 만든 웹 서비스는, 외부 응용 프로그램과 예측 분석 모델 간의 통신용 인터페이스를 제공하는 REST API입니다. 웹 서비스는 예측 모델과 실시간으로 통신하여 예측 결과를 받고 외부 클라이언트 응용 프로그램에 결과를 통합할 수 있는 방법을 제공합니다. 기계 학습 API 서비스는 Azure 기계 학습 REST API의 배포, 호스팅 및 관리에 Microsoft Azure를 활용합니다. 두 가지 유형의 서비스가 Azure 기계 학습 API 서비스를 사용하여 생성되는데, 비동기적인 일괄 액세스를 위한 일괄 처리 실행 서비스와 대기 시간이 짧은 동기 응답을 위한 요청 응답 서비스입니다.
예측 모델은 작업 영역 내 스테이징에서 활용할 수 있습니다. 또한 기계 학습 API 서비스는 웹 서비스용 도움말 페이지도 생성합니다. 웹 서비스 도움말 페이지는 C#, R 및 Python으로 웹 서비스를 호출하는 코드 샘플을 제공합니다. 서비스에 대한 대화형 호출을 하여 웹 서비스를 테스트할 수 있습니다. 그런 다음 몇 번의 클릭만으로 스테이징된 웹 서비스를 프로덕션 상태로 전환할 수 있습니다. 프로덕션 환경에서는 배포된 서비스를 모니터할 수 있을 뿐 아니라 Azure 포털의 사용량 및 오류를 추적할 수 있습니다. 웹 서비스를 업데이트하는 작업은 기계 학습 스튜디오에서 모델을 업데이트하고 변경 내용을 스테이징 서비스에 적용하는 작업만큼 간단합니다.
4. Microsoft Azure 기계 학습에는 어떻게 접근합니까?
Azure 기계 학습을 시작하려면 시작하기 페이지를 방문하세요. Azure 기계 학습 센터에서 서비스에 대한 업데이트를 받고, 기계 학습 팀 블로그의 최신 내용을 보고, 포럼을 통해 기계 학습 커뮤니티에 참여하고, 제품 도움말에 액세스하고, 모델 갤러리를 보고, 제품 로드맵을 형성하는 데 활용하도록 서비스에 대한 피드백을 제공할 수 있습니다.
결제
5. 기계 학습 결제는 어떤 방식으로 이루어집니까?
Azure 기계 학습 스튜디오 서비스 요금은 활성 실험의 계산 시간 단위로 청구되며 부분 시간은 일할 계산되어 청구됩니다. Azure 기계 학습 API 서비스 요금은 1,000번의 예측 API 호출당 청구되며, 예측을 활발하게 실행할 경우 계산 시간 단위로 청구됩니다. 1,000번보다 작은 예측 수량 및 부분 계산 시간에 대한 청구는 일할 계산됩니다.
가입한 작업 영역당 요금이 집계됩니다. 각 작업 영역 내에는 다음과 같이 3가지 항목에 대한 요금이 표시됩니다.
· 스튜디오 실험 시간 - 이 측정기는 기계 학습 스튜디오에서 실험을 실행하고 스테이징 환경에서 예측을 실행하여 발생하는 모든 계산 요금을 집계합니다.
· API 서비스 예측 시간 - 이 측정기는 프로덕션에서 실행하는 웹 서비스로 발생된 계산 요금을 포함합니다.
· API 서비스 예측(1000개 단위) - 이 측정기는 프로덕션 웹 서비스에 대한 호출당 발생하는 요금을 포함합니다.
가격 정보에 대해서는 가격 정보 페이지(http://azure.microsoft.com/pricing/details/machine-learning/)를 참조하세요.
6. Azure 기계 학습의 무료 평가판이 있습니까?
Azure 기계 학습은 Azure 무료 평가판의 일부입니다. Azure 무료 평가판에 등록하면 한 달 동안 모든 Azure 서비스를 사용해볼 수 있습니다. Azure 무료 평가판에 대한 자세한 내용은 http://azure.microsoft.com/pricing/free-trial-faq/를 참조하세요.
기계 학습 스튜디오
7. Azure 기계 학습에서 지원하는 데이터 소스는 무엇입니까?
로컬 파일을 데이터 집합으로 업로드하거나 판독기 모듈을 사용하여 데이터를 가져오는 두 가지 방법으로 기계 학습 스튜디오에 데이터를 로드할 수 있습니다. 기계 학습 스튜디오에서 새 데이터 집합을 추가하여 로컬 파일을 데이터 집합으로 업로드할 수 있습니다. 지원되는 파일 형식에 대한 자세한 내용은 기계 학습 스튜디오의 데이터 가져오기 도움말 항목을 참조하세요.
판독기 모듈은 Azure 테이블, Azure Blob, SQL 데이터베이스(Azure) 또는 HDInsight에서 데이터를 읽을 수 있습니다. 또한 http를 통해 데이터 소스에서 데이터를 가져올 수 있습니다. 자세한 내용은 기계 학습 스튜디오의 판독기 모듈에 대한 도움말 항목을 참조하세요.
8. 내 데이터 집합은 얼마나 확장할 수 있습니까?
기계 학습 스튜디오는 최대 10GB의 학습 데이터 집합을 지원합니다. 웹 서비스에 대한 데이터 집합 크기에는 제한이 없습니다. 또한 수집 전에 Hive 또는 SQL 쿼리를 통해 더 큰 데이터 집합도 샘플링할 수 있습니다. 10GB보다 큰 데이터를 사용하여 작업하는 경우 여러 데이터 집합을 만들고 '파티션 및 샘플', '분할' 또는 '결합' 모듈을 사용하여 기계 학습 스튜디오의 데이터 집합을 다시 결합해서 예측 모델을 빌드하는 학습 집합을 만들 수 있습니다. 이러한 모듈에 대한 자세한 내용은 기계 학습 스튜디오의 모듈 도움말을 참조하세요.
2GB보다 큰 데이터 집합의 경우 로컬 파일에서 직접 업로드하지 않고 Azure 저장소 또는 SQL 데이터베이스(Azure)에 데이터를 업로드하거나 HDInsight를 사용하는 것이 좋습니다.
9. 기계 학습 스튜디오에서 지원되는 기존 기계 학습 알고리즘은 무엇입니까?
기계 학습 스튜디오는 Microsoft Research에서 개발된 확장 가능한 고급 의사 결정 트리, Bayesian 권장 시스템, 심층적인 신경망, 의사 결정 정글 등 최신 기계 학습 알고리즘을 제공합니다. Vowpal Wabbit과 같은 확장 가능한 오픈 소스 기계 학습 패키지도 포함되어 있습니다. 기계 학습 스튜디오는 여러 클래스의 이진 분류, 회귀 및 클러스터링을 위한 기계 학습 알고리즘을 지원합니다. 기계 학습 알고리즘의 전체 목록은 기계 학습 스튜디오에서 확인할 수 있습니다.
10. 원하는 기계 학습 알고리즘, 데이터 소스, 데이터 형식, 데이터 변환 작업이 Azure 기계 학습 스튜디오에 없는 경우 어떻게 해야 합니까?
사용자 피드백 포럼을 방문하면 Microsoft에서 추적 중인 기능 요청을 확인할 수 있습니다. 원하는 기능이 이미 요청된 경우 해당 요청에 투표할 수 있습니다. 원하는 기능이 없는 경우 새로운 요청을 만드세요. 이 포럼에서 요청의 상태를 확인할 수도 있습니다. Microsoft는 이 목록을 긴밀하게 추적하여 기능의 사용 가능성 상태를 자주 업데이트합니다.
11. 기존 코드를 기계 학습 스튜디오에 가져올 수 있습니까?
기계 학습 스튜디오는 현재 R을 지원하므로, 기계 학습 스튜디오에 기존 R 코드를 가져와서 Azure 기계 학습 제공 학습자를 사용하여 동일한 실험에서 실행하고 Azure 기계 학습을 통해 웹 서비스로 게시할 수 있습니다. Azure 기계 학습은 R의 분석 자산을 엔터프라이즈급 프로덕션 웹 서비스에 적용할 수 있는 가장 빠른 방법입니다. 기계 학습 스튜디오에 R 코드 및 시각화 기능을 가져오는 방법에 대해서는 기계 학습 스튜디오 도움말 항목인 R을 사용한 확장성을 참조하세요.
12. 기계 학습 스튜디오에서 사용 가능한 R 패키지는 무엇입니까?
기계 학습 스튜디오는 현재 350개 이상의 R 패키지를 지원하며 이 목록은 지속적으로 늘어나고 있습니다. 지원되는 R 패키지의 목록을 얻는 방법에 대해서는 기계 학습 스튜디오 도움말 항목인 R을 사용한 확장성을 참조하세요. 원하는 패키지가 이 목록에 없는 경우 사용자 피드백 포럼에서 패키지 이름을 제공해 주세요.
13. 어떤 경우에 내 예측 모델을 일괄 처리 실행 서비스로 실행하고 어떤 경우에 요청/응답 웹 서비스를 실행합니까?
RRS(요청-응답 서비스)는 대기 시간이 짧고, 확장성이 높은 웹 서비스로, 실험 환경에서 생성하여 게시하는 상태 비저장 모델에 대한 인터페이스를 제공하는 데 사용됩니다. BES(일괄 처리 실행 서비스)는 데이터 레코드의 배치에 대한 점수를 비동기적으로 계산하는 서비스입니다. BES의 입력은 RRS에 사용되는 데이터 입력과 유사합니다. 가장 중요한 차이는 BES에서는 Blob, Azure의 테이블, SQL 데이터베이스(Azure), HDInsight(Hive 쿼리), HTTP 소스 등의 다양한 소스에서 레코드 블록을 읽는다는 것입니다. 점수를 계산한 결과는 Azure Blob 저장소의 파일 출력이며 저장소 끝점은 응답으로 반환됩니다.
일괄 처리 실행 서비스는 대량의 데이터 지점에 대한 점수를 일괄로 계산해야 하거나 데이터 중 상당량이 이미 Azure 저장소 또는 Hadoop 클러스터의 파일 형식인 경우에 유용합니다. 웹 서비스에서 데이터를 모델로 전송하기 전에 데이터를 변환할 수 있으므로 단지 주간 트랜잭션 데이터의 끝을 일괄 처리 서비스로 가리켜서 데이터를 변환하여 결과를 제공할 수 있습니다.
요청 응답 서비스는 모바일 또는 웹 응용 프로그램을 통해 제공되는 콘텐츠 또는 사용자 동작을 안내하거나 라이브 대시보드를 제공하기 위해 예측 분석이 실시간으로 필요한 경우에 유용합니다.
14. 배포된 서비스 프로덕션의 모델은 어떻게 업데이트합니까?
이미 배포된 서비스의 예측 모델을 업데이트하는 작업은 학습된 모델을 빌드하여 저장하는 데 사용된 실험을 수정하고 다시 실행하는 작업만큼 간단합니다. 사용 가능한 새 버전의 학습된 모델을 작성하면 기계 학습 스튜디오에서 스테이징 웹 서비스를 업데이트할지 여부를 묻습니다. 스테이징 웹 서비스에 업데이트를 적용한 후에는 동일한 업데이트를 프로덕션 웹 서비스에도 적용할 수 있습니다. 배포된 웹 서비스를 업데이트하는 방법에 대한 자세한 내용은 기계 학습 스튜디오 도움말 항목인 웹 서비스 업데이트를 참조하세요.
보안 및 사용 가능성
15. 기본적으로, 프로덕션에 배포된 웹 서비스의 http 끝점에 대한 액세스 권한을 갖는 사람은 누구입니까? 끝점에 대한 액세스는 어떻게 제한합니까?
예측 모델을 프로덕션 상태로 전환하면 Azure 포털에서 배포된 웹 서비스의 URL을 나열합니다. 스테이징 서비스 URL에는 기계 학습 스튜디오 환경의 웹 서비스 섹션에서 액세스할 수 있고, 프로덕션 서비스 URL에는 Azure 포털의 기계 학습 섹션에서 액세스할 수 있습니다. Azure 포털 환경과 기계 학습 스튜디오의 웹 서비스 대시보드에서 각기 스테이징과 프로덕션 웹 서비스 모두에 액세스할 수 있는 액세스 키가 제공됩니다. 액세스 키는 프로덕션 및 스테이징의 웹 서비스를 호출하는 데 필요합니다.
16. 프로덕션에 배포된 내 웹 서비스는 어떻게 모니터합니까?
예측 모델을 프로덕션 상태로 전환한 후에는 Azure 포털에서 모니터할 수 있습니다. 배포된 각 서비스에는 고유한 대시보드가 있어, 이 대시보드에서 해당 서비스에 대한 모니터링 정보를 볼 수 있습니다.
지원 및 교육
17. Azure 기계 학습에 대한 교육은 어디에서 받을 수 있습니까?
Azure 기계 학습 센터에서 비디오 자습서와 방법 가이드를 호스트합니다. 이러한 단계별 가이드에서는 서비스를 소개하고, 데이터 가져오기, 데이터 정리, 예측 모델 구성, Azure 기계 학습에서 프로덕션으로 전환의 데이터 과학 수명 주기 전체를 안내해 줍니다.
비디오 자습서에서는 기계 학습 스튜디오와 기계 학습 API 서비스를 둘러볼 수 있습니다. 비디오 자습서는 광범위한 서비스, 가장 많이 사용되는 데이터 가져오기, 모듈 정리 및 처리, 예측 모델 빌드, 예측 모델 배포를 시연합니다. 또한 비디오 자습서에서는 작업 영역 프로비전, 프로덕션에 스테이징된 모델 배포 등과 같은 작업도 다룹니다.
Microsoft는 기계 학습 센터에 새로운 자료를 계속 추가할 예정입니다. 사용자 피드백 포럼에서 기계 학습 센터의 추가 학습 자료를 제출할 수 있습니다.
18. Azure 기계 학습에 대한 지원은 어떻게 받습니까?
Azure 기계 학습은 Azure 지원 제공물의 일부로 지원됩니다. Azure 기계 학습에 대한 기술 지원을 받으려면 '기계 학습'을 서비스로 선택하세요. 그러면 지원 티켓을 제출할 수 있는 항목의 범주가 제공됩니다. Azure 지원 제공물에 대한 자세한 내용은 http://azure.microsoft.com/support/options/를 참조하세요.
또한 Azure 기계 학습은 MSDN에 커뮤니티 포럼을 갖고 있으며, 여기에서 Azure 기계 학습 관련 질문을 할 수 있습니다. 이 포럼은 Azure 기계 학습 팀에서 모니터합니다. Azure 포럼을 방문해보세요.
'AZ ml' 카테고리의 다른 글
| 음식점 추천 기계학습 모델 결과 해석하기 (6) (0) | 2016.01.13 |
|---|---|
| 기계학습의 모델결과 해석방법 (5) (0) | 2016.01.13 |
| 신용위험 예측 기계학습 모델 만들기 (4) (0) | 2016.01.13 |
| 기계학습 교본: Azure ML스튜디오에서 첫 번째 실험 만들기 (3) (0) | 2016.01.13 |
| What is Azure Machine Learning Studio? Azure기계학습 스튜디오란 무엇인가요? (2) (0) | 2016.01.06 |
댓글